BloodHound: Mappa Active Directory e Trova Attack Paths

Scopri come usare BloodHound per analizzare Active Directory e trovare escalation di privilegi. Tool essenziale per Red Team e attacchi interni simulati.
- Pubblicato il 2026-01-23
- Tempo di lettura: 6 min
BloodHound: Mappa Active Directory e Trova Attack Paths #
BloodHound è lo strumento fondamentale per analizzare la sicurezza di un dominio Active Directory. Trasforma dati complessi (utenti, gruppi, computer, ACL, sessioni, GPO) in una mappa grafica interattiva, rivelando relazioni nascoste e percorsi di escalation che spesso esistono “per sbaglio” a causa di configurazioni stratificate nel tempo.
Il motivo per cui BloodHound è così potente è semplice: Active Directory è una rete di relazioni, non un elenco di utenti. E quando le relazioni diventano troppe (privilege creep), anche un utente “normale” può avere – indirettamente – un percorso verso privilegi elevati.
Obiettivo pratico: usare BloodHound per vedere e correggere percorsi pericolosi (audit e hardening) o per documentare in modo chiaro le evidenze in un penetration test autorizzato.
Definizione operativa: cos’è BloodHound? #
BloodHound è una piattaforma di analisi della sicurezza per ambienti Active Directory (e, in alcuni contesti, anche ibridi). Sfrutta la teoria dei grafi per:
- raccogliere dati dal dominio tramite “collectors” (ingestors)
- memorizzarli in un database a grafo (Neo4j o stack CE)
- analizzarli con query predefinite e custom
- visualizzare percorsi, relazioni e privilegi che contano davvero
Se stai facendo un assessment serio, BloodHound ti fa rispondere a domande concrete:
- Quali utenti/gruppi hanno permessi “strani” su oggetti critici?
- Chi può modificare GPO o ACL sensibili?
- Dove ci sono sessioni amministrative eccessive?
- Quali host sono punti di pivot “facili”?
Architettura e componenti tecnici (chi fa cosa) #
BloodHound lavora con un’architettura a tre livelli:
1) Database grafico (Neo4j / stack CE) #
È il “cervello” che memorizza:
- nodi (User, Group, Computer, GPO, OU…)
- relazioni (MemberOf, AdminTo, HasSession, GenericAll, WriteDacl…)
Questo modello è perfetto per trovare percorsi multi-step.
2) Collettori (Ingestors) #
Sono gli agenti che raccolgono dati dal dominio:
- SharpHound (C#): collector principale e ufficiale (EXE / PS1)
- bloodhound-python: alternativa comoda su Linux/Kali
3) GUI BloodHound #
Interfaccia per:
- importare i dati
- eseguire query built-in
- fare pathfinding (source → target)
- analizzare Node Info e Control Rights
- usare query Cypher (Neo4j) quando serve
Installazione: da zero al primo grafico #
Qui ti metto le 2 strade migliori (come nei link che hai incollato), ordinate per utilità nel 2026:
- BloodHound CE con Docker (Kali) – consigliato
- BloodHound “legacy” + Neo4j Desktop (Windows/lab) – ancora usato in tanti lab
A) Installazione su Kali (Metodo Moderno 2026): BloodHound CE con Docker #
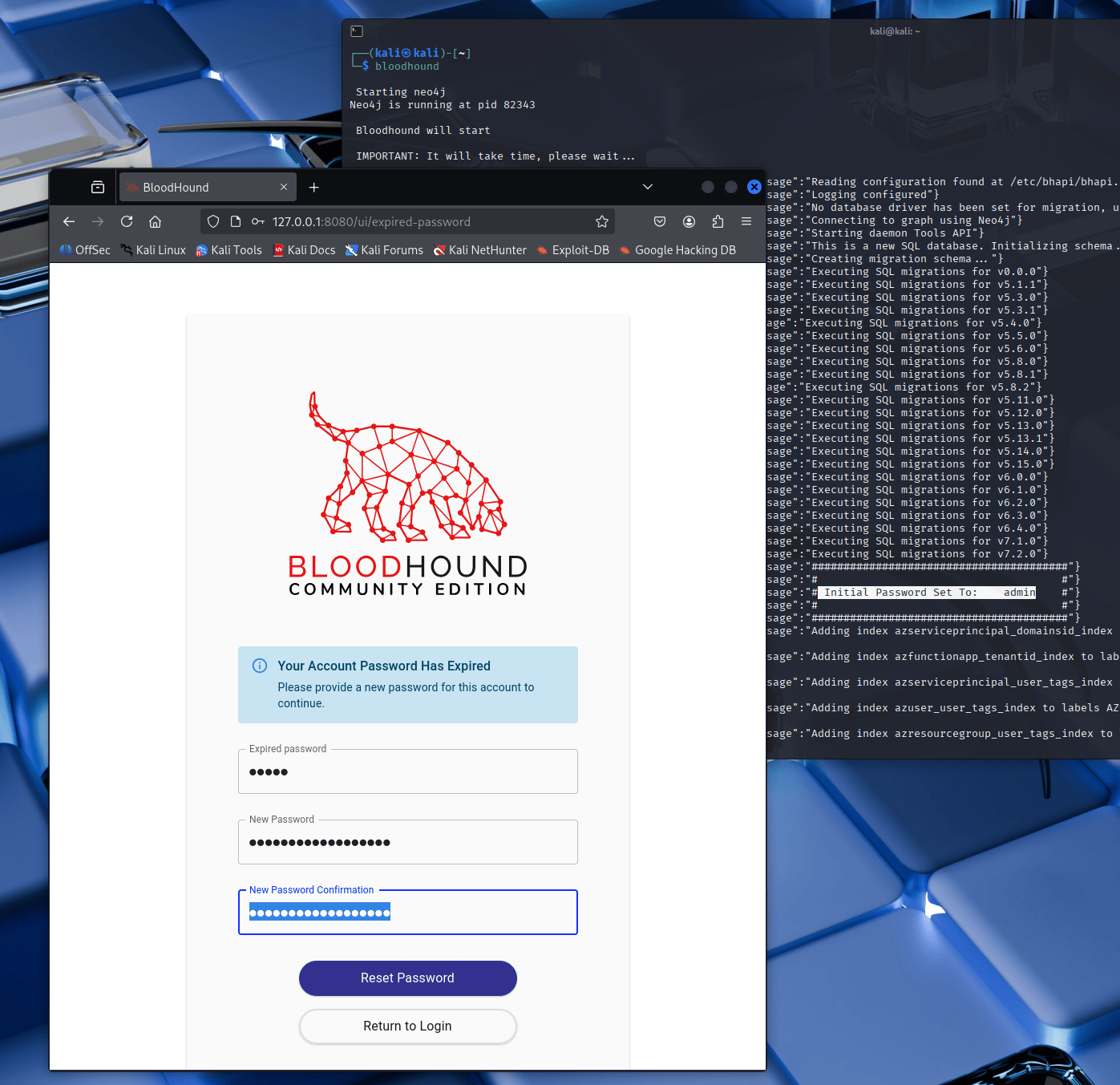
Questo è il metodo più pulito: gestisci servizi e dipendenze con container, riduci rogne di Neo4j installato male, e aggiorni più facilmente.
Step 1 — installa Docker e Compose #
sudo apt update
sudo apt install -y docker.io docker-compose
sudo systemctl enable --now docker
sudo usermod -aG docker $USER
newgrp dockerStep 2 — scarica e avvia BloodHound CE #
mkdir -p ~/bloodhound-ce && cd ~/bloodhound-ce
curl -L https://ghst.ly/getbhce -o docker-compose.yml
sudo docker-compose up -dStep 3 — verifica che sia tutto su #
sudo docker-compose ps
sudo docker psStep 4 — apri la GUI #
Di solito:
http://localhost:8080
Se la porta non è 8080, te lo dice
docker-compose ps(guarda la colonna “PORTS”).
Problemi tipici (fix rapidi) #
Porte in conflitto (classico se tieni anche la versione legacy):
sudo ss -lntp | grep -E '8080|7474|7687'Stop / restart veloce
cd ~/bloodhound-ce
sudo docker-compose down
sudo docker-compose up -dB) Installazione su Kali (Metodo Tradizionale): Neo4j + BloodHound legacy #
Se vuoi proprio la versione “classica” che gira con Neo4j locale.
sudo apt update && sudo apt install -y bloodhound neo4j
sudo neo4j start
bloodhoundPoi apri Neo4j su:
http://localhost:7474
Login iniziale spesso:
- user
neo4j - pass
neo4je ti obbliga a cambiarla.
C) Installazione su Windows (lab): Neo4j Desktop + BloodHound legacy #

Questo segue esattamente l’approccio che hai incollato (tipo Rich / Ali Rodoplu), ed è perfetto per lab e demo.
Step 1 — prepara cartella (anti-casino) #
Crea:
C:\Tools\BloodHoundoppure:
C:\TempConsiglio: tenerlo in una cartella unica aiuta anche se devi gestire eccezioni AV in lab.
Step 2 — installa Neo4j Desktop #
Scarica Neo4j Desktop dal sito ufficiale e installalo. Poi:
- apri Neo4j Desktop
- crea un DBMS (es:
BloodHoundDB) - imposta una password (non “password”, dai…)
- Start DB
Verifica:
- apri
http://localhost:7474 - user:
neo4j - pass: quella che hai impostato
Step 3 — avvia BloodHound #
Scarica BloodHound dai rilasci GitHub (legacy), estrai lo zip e avvia BloodHound.exe.
Login:
- user:
neo4j - pass: password DB
Se vedi “No Database Found”: Neo4j non è partito, o DB non è in running.
Raccolta Dati: SharpHound e bloodhound-python (senza questo BloodHound è vuoto) #
1) SharpHound (Windows) — raccolta standard #
SharpHound sta spesso in:
...\BloodHound-win32-x64\resources\app\CollectorsComando base (completo) #
SharpHound.exe --CollectionMethods AllOutput: uno ZIP tipo:
2026xxxx_BloodHound.zipImport:
- BloodHound → Upload / Import Data → selezioni ZIP
Suggerimento “audit-friendly”: All è completo ma può essere lento su domini grandi. Se devi fare una prima passata rapida, puoi partire da
Session,LocalAdmin,ACL(sono spesso i più “parlanti” per rischio reale).
Raccolta Strategica con SharpHound (Metodo Operativo Fase per Fase) #
Fase 1 — Primo Accesso (Low Noise Enumeration) #
Obiettivo: mappare relazioni principali senza generare traffico eccessivo sui Domain Controller.
SharpHound.exe --CollectionMethods Default,GroupMembership --Throttle 1000 --ExcludeDomainControllersCosa raccoglie:
- Struttura base del dominio
- Membership tra utenti e gruppi
- Catene MemberOf utili per escalation indirette
Perché usarlo:
- Riduce visibilità nei log
- Ideale appena ottieni credenziali valide
- Permette una prima analisi shortest path senza rumore inutile
Fase 2 — Movimento Laterale Mirato #
Obiettivo: identificare combinazioni AdminTo + Session attive.
SharpHound.exe --CollectionMethods Session,LocalAdmin --StealthCosa raccoglie:
- Utenti con diritti amministrativi locali
- Sessioni attive su host
- Relazioni AdminTo sfruttabili
Perché usarlo:
- Trova pivot reali
- Evidenzia combinazioni User → AdminTo → HasSession
- Modalità
--Stealthusa thread singolo (meno rumorosa)
Fase 3 — Escalation tramite ACL e Permessi Nascosti #
Obiettivo: trovare diritti abusabili su oggetti AD.
SharpHound.exe --CollectionMethods ACL,Container,DCOMQui emergono:
- GenericAll
- WriteDacl
- WriteOwner
- ForceChangePassword
- Deleghe DCOM sfruttabili
Questa fase rivela percorsi indiretti che non sono visibili tramite semplice membership.
Fase 4 — Monitoraggio Sessioni (Advanced Engagement) #
Obiettivo: intercettare login privilegiati durante l’assessment.
SharpHound.exe --CollectionMethods Session --Loop --LoopDuration 01:00:00Funzionamento:
- Monitora nuove sessioni per 1 ora
- Aggiorna dinamicamente il dataset
- Utile quando si attende login di account privilegiati
Differenza Operativa #
SharpHound.exe --CollectionMethods AllÈ completo, ma:
- Non distingue fasi operative
- Genera più traffico
- Non è ottimizzato per engagement reali
L’approccio fase-per-fase permette controllo, precisione e migliore gestione del rumore durante un penetration test autorizzato.
2) bloodhound-python (Kali/Linux) — raccolta comoda #

Installazione #
python3 -m pip install bloodhoundRaccolta completa #
mkdir -p ~/bloodhound-data
cd ~/bloodhound-data
bloodhound-python -d DOMINIO.LOCAL -u utente -p 'Password' -ns IP_DC -c allI file vengono creati nella directory (a volte JSON multipli). Li importi nella GUI (CE o legacy) dall’area di ingest/import.
Import dei dati (qui la gente si incastra) #
Import in BloodHound legacy #
- pulsante Upload Data
- carichi lo ZIP di SharpHound
Import in BloodHound CE #
- sezione ingest / upload
- carichi ZIP o file generati (dipende dalla UI)
Se importi e “non vedi nulla” #
Controlla questi 4 punti:
- Neo4j (legacy) è avviato? (o container CE su?)
- credenziali DB corrette?
- hai importato lo ZIP giusto (non zip annidati)?
- collector compatibile con la versione? (soprattutto se mischi vecchio/nuovo)
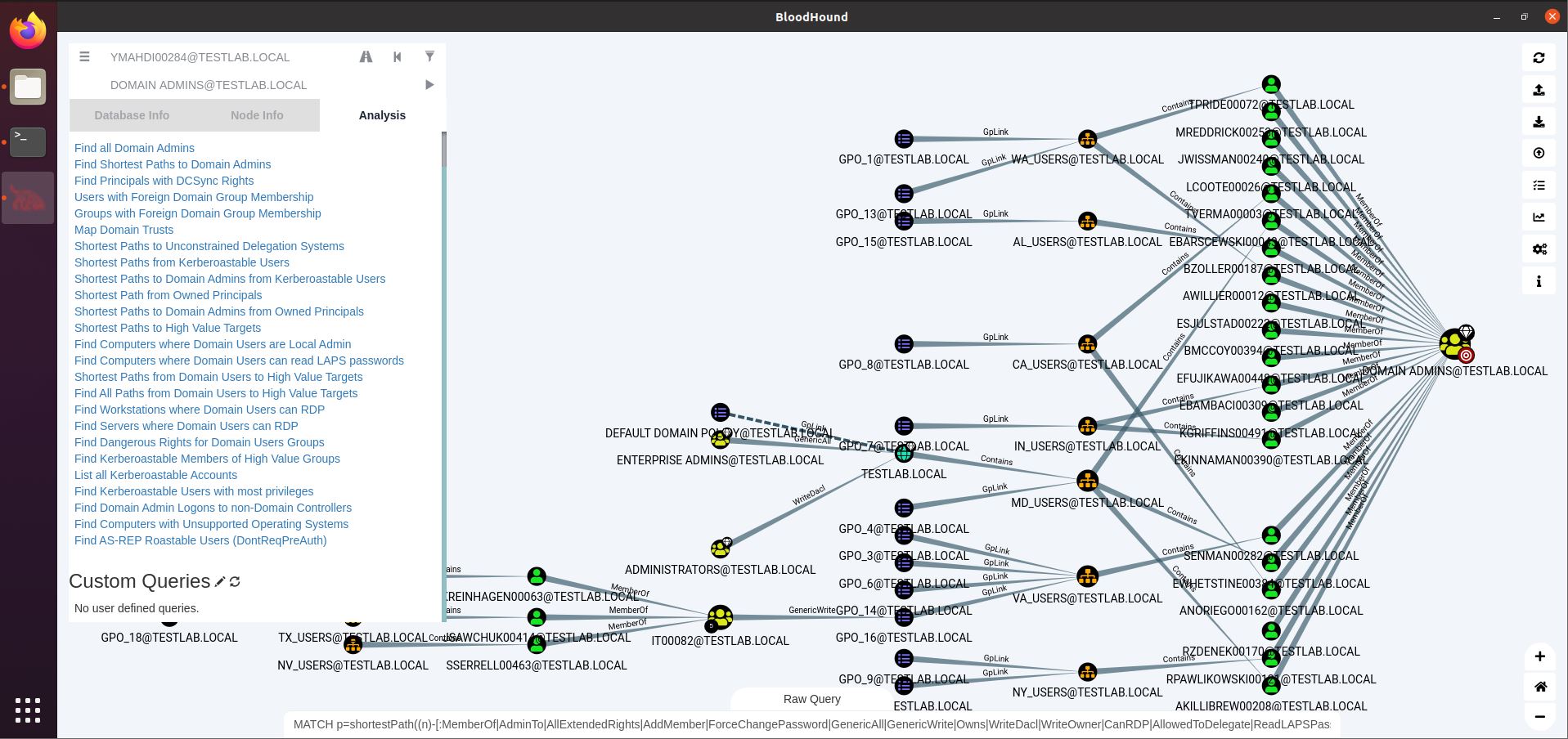
Uso pratico della GUI: come analizzare davvero (non solo guardare un grafo) #
1) Parti dalle query predefinite “che spaccano” #
Le più usate in assessment seri:
- Find Shortest Paths to Domain Admins
- Find Principals with DCSync Rights
- Find Computers with Unconstrained Delegation
- Users with Most Local Admin Rights
- Dangerous ACLs (WriteDacl/GenericAll/WriteOwner)
In ottica difensiva: queste query ti danno subito una backlog di remediation.
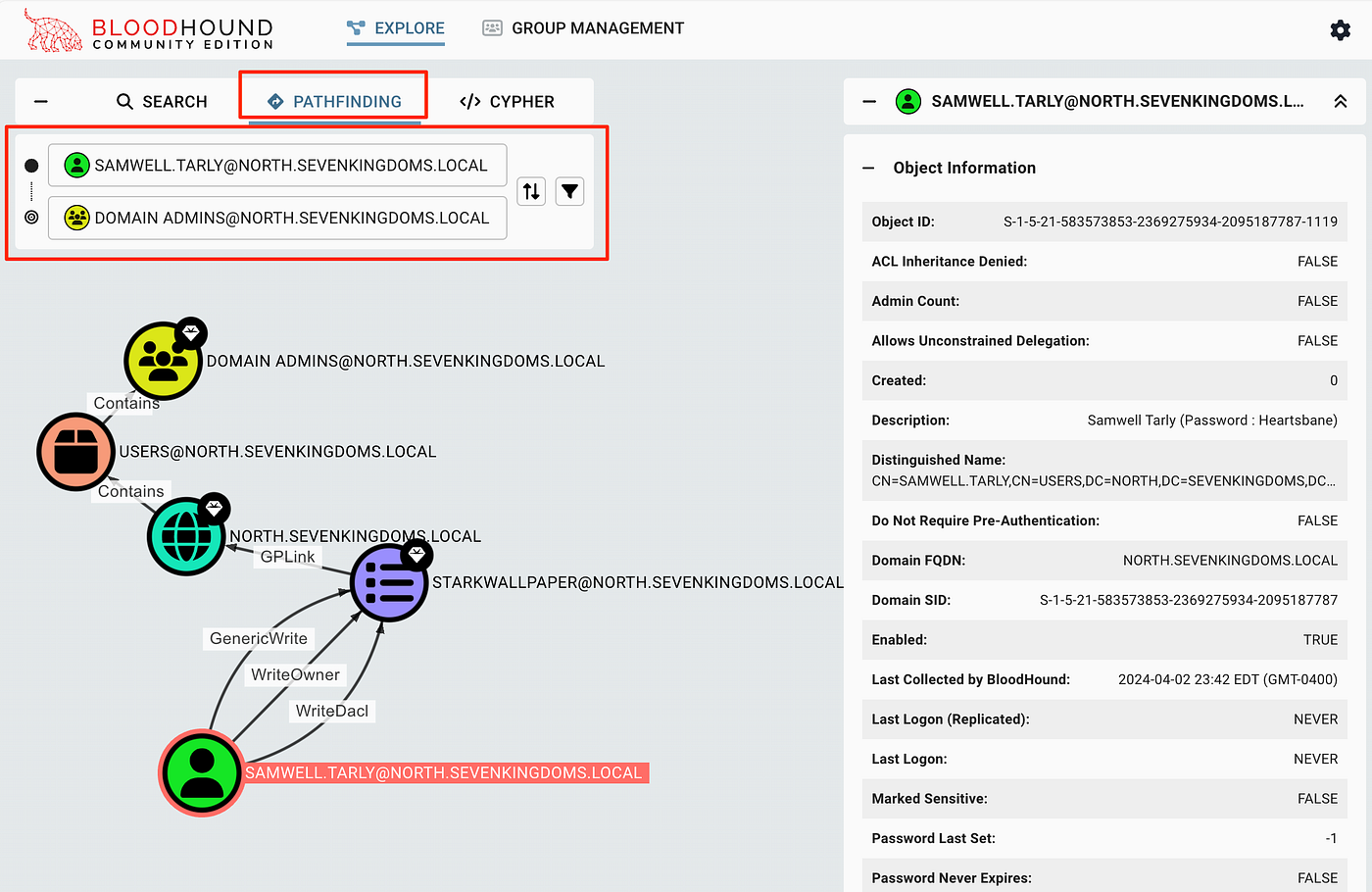
2) Usa Pathfinding (source → target) #
Esempio:
- Source: un utente compromesso (es.
j.smith) - Target:
DOMAIN ADMINSoDC
BloodHound ti disegna il percorso e tu lo leggi come una catena:
- membership → admin rights → session → controllo gruppo → ecc.
3) Node Info: il pannello che vale oro #
Clicchi un nodo e trovi:
- Group Membership
- Local Admin Rights
- Sessions
- Inbound/Outbound Control Rights
Regola pratica:
Inbound = chi può controllare questo oggetto Outbound = cosa può controllare questo oggetto
E qui trovi le cose “nascoste” che fanno male: ForceChangePassword, WriteDacl, GenericAll, ecc.
Neo4j / Cypher: esempi utili “da report” #
Kerberoastable users (lista nomi pulita) #
MATCH (u:User)
WHERE u.hasspn = true
RETURN u.name
ORDER BY u.nameUtenti inattivi da 90 giorni #
MATCH (u:User)
WHERE u.lastlogon < (datetime().epochseconds - (90 * 86400))
AND NOT u.lastlogon IN [-1.0, 0.0]
RETURN u.name
ORDER BY u.nameRelazioni ACL pericolose verso gruppi #
MATCH (u:User)-[r:GenericAll|WriteDacl|WriteOwner|GenericWrite]->(g:Group)
RETURN u.name, type(r), g.name
ORDER BY type(r)Scenario pratico (come nei link): dal primo utente → percorso critico #
Immagina di avere le credenziali di j.smith@corp.local.
BloodHound mostra:
j.smithè MemberOfHelpDesk_OpsHelpDesk_Opsha AdminTo suSRV-WEB01- su
SRV-WEB01c’è una HasSession disvc_sql svc_sqlè MemberOfDomain Admins
Tradotto: il rischio sta nella combinazione (privilegi locali + sessioni + gruppi). In difesa, la correzione spesso è:
- togliere AdminTo non necessario
- ridurre sessioni admin persistenti
- usare tiering e workstation amministrative dedicate
Hardening e audit difensivo (la parte che fa “SEO buono” perché è utile) #
Se vuoi ridurre davvero i percorsi che BloodHound trova, questi sono i fix che contano:
- Ripulisci gruppi privilegiati (membership annidate e storiche)
- Riduci ACL pericolose su OU/GPO/gruppi (WriteDacl/WriteOwner/GenericAll)
- Separa Tier 0/1/2 (admin AD non deve loggarsi su workstation utenti)
- Riduci admin locali e gestisci password locali (es. LAPS)
- Controlla deleghe Kerberos (unconstrained/constrained)
- Rivedi GPO e deleghe di gestione (chi può modificare cosa)
BloodHound non è solo “attacco”: è un tool di governance dei privilegi.
FAQ #
Qual è la differenza tra BloodHound e SharpHound? #
BloodHound è la piattaforma di analisi/visualizzazione. SharpHound è il collector che raccoglie i dati dal dominio e li produce in un formato importabile.
Posso usare BloodHound su Kali Linux? #
Sì. Puoi usare la versione legacy con Neo4j oppure la BloodHound CE con Docker (molto più semplice da mantenere).
Perché BloodHound “non mostra nulla” dopo l’avvio? #
Perché non hai ancora importato dati. Devi eseguire SharpHound o bloodhound-python e importare l’output.
Serve davvero Neo4j? #
Nella legacy sì, è essenziale. Nella CE lo stack è containerizzato, ma concettualmente il database a grafo resta il cuore.
Come capisco quali findings sono davvero critici? #
Priorità alta per:
- DCSync rights
- deleghe pericolose
- ACL su gruppi Tier-0
- GPO modificabili da non-admin
- sessioni admin su server “facili”
BloodHound è utile anche per i difensori? #
Sì: è uno dei modi migliori per scoprire privilege creep e relazioni pericolose prima che lo faccia qualcun altro.
HackITA — Supporta la Crescita della Formazione Offensiva #
Se questo contenuto ti è stato utile e vuoi contribuire alla crescita di HackITA, puoi supportare direttamente il progetto qui:
Il tuo supporto ci permette di sviluppare lab realistici, guide tecniche avanzate e scenari offensivi multi-step pensati per professionisti della sicurezza.
Vuoi Testare la Tua Azienda o Portare le Tue Skill al Livello Successivo? #
Se rappresenti un’azienda e vuoi valutare concretamente la resilienza della tua infrastruttura contro attacchi mirati, oppure sei un professionista/principiante che vuole migliorare con simulazioni reali:
Red Team assessment su misura, simulazioni complete di kill chain e percorsi formativi avanzati progettati per ambienti enterprise reali.
Link utili #
Neo4j Desktop: https://neo4j.com/download/
BloodHound releases: https://github.com/BloodHoundAD/BloodHound/releases
DarthSidious (BloodHound notes): https://hunter2.gitbook.io/darthsidious/enumeration/bloodhound