Rpcinfo: Enumerazione Dei Servizi RPC in Ambienti Unix

Rpcinfo permette di identificare i servizi RPC attivi su host Unix/Linux. Fondamentale per il recon e l’analisi di potenziali vettori di attacco remoti.
- Pubblicato il 2026-01-25
- Tempo di lettura: 10 min
Rpcinfo: enumerare servizi RPC e porte dinamiche (rpcbind/portmapper) #
Se vedi la porta 111 aperta in lab e non capisci cosa ci gira dietro, rpcinfo ti trasforma quel “segnale” in una lista concreta di servizi RPC, versioni e porte reali.
Intro #
rpcinfo è un comando che interroga rpcbind/portmapper per scoprire quali programmi RPC sono registrati su un host e su quali porte stanno ascoltando.
In un pentest da lab è utile perché molti servizi RPC usano porte dinamiche: un semplice scan che trova 111/tcp o 111/udp non ti dice quali servizi sono effettivamente esposti (tipico caso: NFS + mountd). Se stai mappando una LAN interna, prima devi vedere chi è vivo (es. /articoli/arp-scan/ o /articoli/netdiscover/), poi passi a identificare i servizi “back-end” dietro RPC.
Cosa farai/imparerai:
- leggere e interpretare l’output di
rpcinfo(program number, version, proto, port) - verificare velocemente se un servizio è davvero raggiungibile (TCP/UDP)
- capire quando passare a enum NFS (es.
/articoli/showmount/) - evitare falsi negativi (firewall, UDP, registrazioni “fantasma”)
Nota etica: tutto quanto segue è solo per ambienti autorizzati (lab/CTF/HTB/PG/VM personali).
Cos’è rpcinfo e dove si incastra nel workflow #
In breve:
rpcinfoserve a mappare i servizi RPC registrati surpcbind(porta 111) e a scoprire porte/servizi reali che altrimenti restano nascosti.
Quando fai recon “network-first”, rpcinfo entra subito dopo:
- discovery host (ARP/ICMP) e scan porte base
- conferma della presenza di
rpcbindsu111(TCP/UDP) - enumerazione RPC per capire se vale la pena spingere su NFS/NIS/altro
Quando NON usarlo: se 111 è chiusa o filtrata e non hai visibilità di rete (es. segmentazione/ACL), rpcinfo ti darà poco o nulla: passa a scan mirati e verifica da un vantage point corretto.
Installazione, verifica versione e quick sanity check #
In breve: su Kali spesso è già disponibile; se manca, lo installi e poi fai un sanity check su
111in TCP e UDP.
Perché: prima di interrogare RPC devi assicurarti che rpcbind sia raggiungibile.
Cosa aspettarti: rpcinfo presente nel PATH e 111 visibile almeno su uno tra TCP/UDP (dipende dal target).
Comando:
which rpcinfo && rpcinfo -h | headInterpretazione: se which non trova nulla o rpcinfo -h fallisce, installa.
Comando:
sudo apt update
sudo apt install -y rpcbindErrore comune + fix: confondere “pacchetto installato” con “servizio attivo sul target”. Qui stai installando sul tuo attacker box, non sul target.
Perché: confermare la raggiungibilità di 111 riduce falsi negativi.
Cosa aspettarti: 111/tcp e/o 111/udp aperta o almeno “open|filtered” (in UDP spesso è ambiguo).
Comando:
sudo nmap -n -Pn -sS -p 111 10.10.10.10Esempio di output (può variare):
PORT STATE SERVICE
111/tcp open rpcbindInterpretazione: se 111/tcp è open, puoi testare enumerazione TCP. Se è chiusa ma sospetti RPC, prova UDP.
Comando:
sudo nmap -n -Pn -sU -p 111 10.10.10.10Errore comune + fix: in UDP un “no response” non significa “chiuso”. Aumenta timing/ritentativi o valida con rpcinfo e con un vantage point diverso.
Sintassi base + 3 pattern che userai sempre #
In breve: i tre pattern pratici sono: lista completa (
-p), lista compatta (-s), verifica specifica (-t/-u).
Pattern 1 — Lista completa con porte reali (-p)
#
Perché: vuoi sapere quali programmi RPC ci sono e su quali porte ascoltano.
Cosa aspettarti: una tabella con program, vers, proto, port, service.
Comando:
rpcinfo -p 10.10.10.10Esempio di output (può variare):
program vers proto port service
100000 4 tcp 111 portmapper
100000 3 udp 111 portmapper
100003 3 tcp 2049 nfs
100005 3 udp 20048 mountdInterpretazione: nfs (100003) + mountd (100005) è un segnale forte per passare a enumerazione NFS (vedi /articoli/showmount/). Nota che mountd spesso usa porta dinamica.
Errore comune + fix: prendere per “verità assoluta” una riga registrata. La registrazione può esistere anche se il servizio è instabile: valida con Pattern 3.
Pattern 2 — Vista rapida (-s) per triage
#
Perché: vuoi un colpo d’occhio su servizi/versioni senza fissarti sulle porte. Cosa aspettarti: elenco compatto con versioni e netid.
Comando:
rpcinfo -s 10.10.10.10Esempio di output (può variare):
program version(s) netid(s) service
100000 2,3,4 udp,tcp rpcbind
100003 2,3,4 udp,tcp nfs
100005 1,2,3 udp,tcp mountdInterpretazione: utile per decidere velocemente “spingo su NFS sì/no” senza leggere mille righe.
Errore comune + fix: ignorare le versioni. In lab, differenze tra versioni possono impattare tool/flag successivi (es. comportamento NFS legacy).
Pattern 3 — Verifica attiva di un servizio (-t TCP / -u UDP)
#
Perché: vuoi confermare che il servizio risponda davvero. Cosa aspettarti: risposta positiva se raggiungibile; errori chiari se filtrato/non disponibile.
Comando:
rpcinfo -t 10.10.10.10 mountdEsempio di output (può variare):
program 100005 version 3 ready and waitingInterpretazione: mountd risponde su TCP (se supportato). Ottimo prima di azioni più invasive.
Errore comune + fix: testare TCP quando il servizio è esposto solo via UDP. Se TCP fallisce, prova UDP.
Comando:
rpcinfo -u 10.10.10.10 100005Enumerazione “da lab”: cosa rivela davvero e come leggerlo #
In breve: l’output ti dà segnali operativi: NFS/mountd, nlockmgr/statd, rquota, NIS/ypbind e altri servizi legacy che valgono un approfondimento.
Qui l’obiettivo non è memorizzare ogni program number, ma riconoscere pattern:
100003=nfs(spesso2049)100005=mountd(porta dinamica)100021/100024spesso compaiono in contesti NFS (lock/stat) a seconda dell’implementazione100007=ypbind(NIS legacy: warning in ambienti “vecchi”)
Perché: vuoi trasformare una superficie “RPC generica” in un set di next-step concreti. Cosa aspettarti: poche righe “che contano” che indirizzano la tua enum successiva.
Comando:
rpcinfo -p 10.10.10.10 | egrep "100003|100005|100007"Esempio di output (può variare):
100003 3 tcp 2049 nfs
100005 3 udp 20048 mountd
100007 2 udp 32779 ypbindInterpretazione: NFS è quasi certo; NIS è un indicatore di stack legacy e spesso di hardening debole (in lab è un “punto rosso” da annotare).
Errore comune + fix: basarsi su grep senza guardare protocollo/porta. Se vedi solo udp e hai firewall stateful aggressivo, prepara troubleshooting.
Quando NON usarlo: se stai già sniffando traffico e hai conferma applicativa, non perdere tempo a “ricostruire” via RPC. In quel caso passa a cattura/analisi (es. /articoli/tcpdump/ o /articoli/wireshark/) per validare flussi reali.
Casi d’uso offensivi “da lab” + validazione, detection e mitigazioni #
In breve:
rpcinfonon è un exploit: è un amplificatore di visibilità. Il caso classico è trovare NFS dietro111e passare a enum export e permessi.
Caso 1 — Da 111 a NFS: capire se vale la pena proseguire
#
Perché: vuoi scoprire NFS e mountd anche quando mountd è su porta non standard.
Cosa aspettarti: nfs e mountd presenti nell’elenco; poi verifichi raggiungibilità.
Comando:
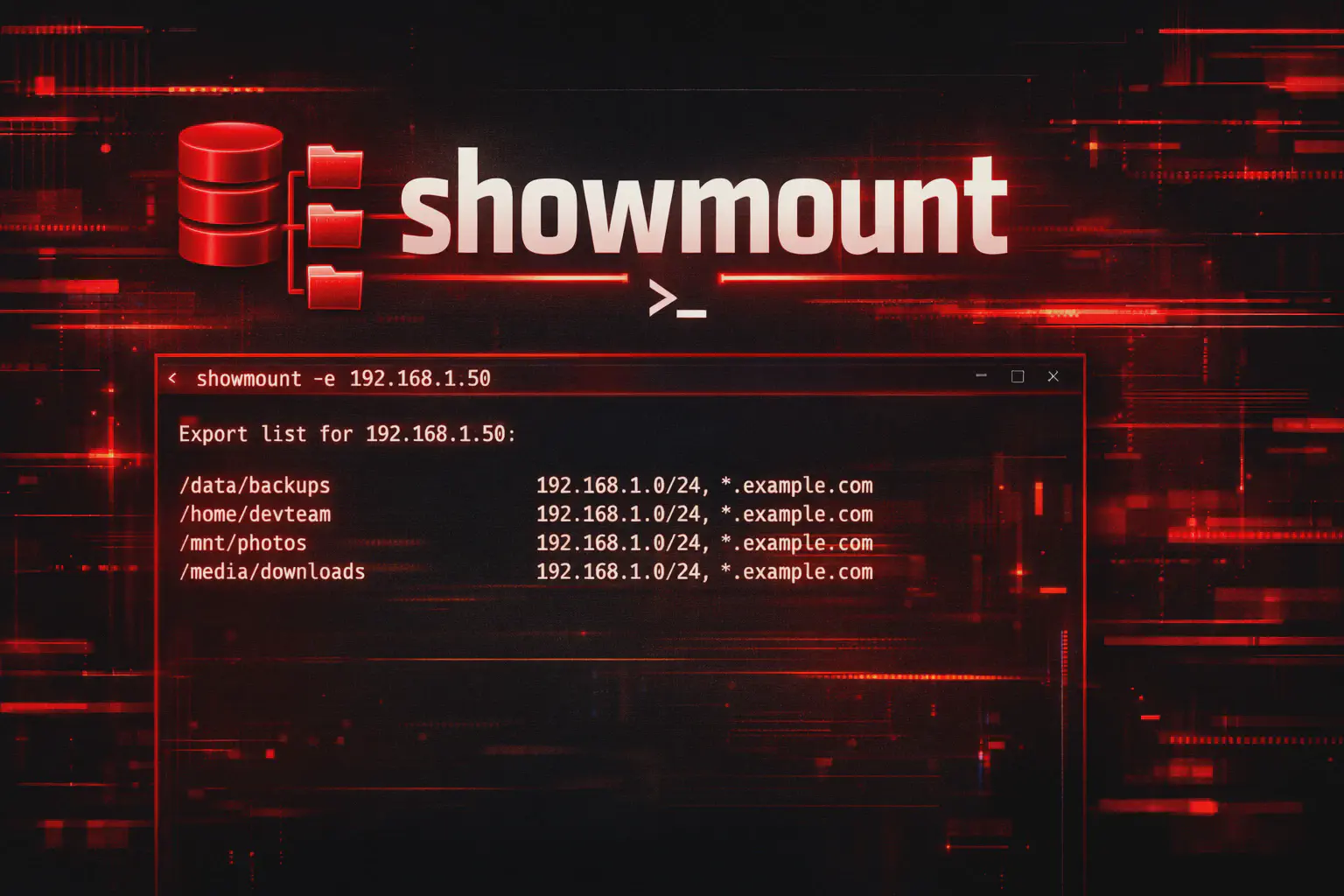
rpcinfo -p 10.10.10.10Interpretazione: se compaiono nfs e mountd, il next-step “pulito” è enumerare export NFS con showmount in lab (guida dedicata: /articoli/showmount/).
Errore comune + fix: saltare direttamente a montaggi o enum “pesante” senza verificare risposte e logging. Prima valida, poi procedi.
Detection (segnali): picchi di query su 111 (TCP/UDP), pattern ripetuti di richieste RPC da un singolo host, seguiti da richieste verso 2049 e la porta dinamica di mountd.
Hardening/mitigazione: limita rpcbind a reti di management, filtra 111 su firewall, usa NFSv4 con controlli adeguati e riduci/chiudi servizi RPC legacy non necessari. In produzione, rpcbind esposto “a caso” è quasi sempre un finding.
Caso 2 — Servizi legacy: individuare NIS (ypbind) e simili #
Perché: stack legacy spesso significa configurazioni vecchie e posture debole.
Cosa aspettarti: presenza di program number “sospetti” (es. 100007) e porte alte dinamiche.
Comando:
rpcinfo -p 10.10.10.10 | grep 100007Esempio di output (può variare):
100007 2 udp 32779 ypbindInterpretazione: in lab, segnalo come “investigare”: è un indizio, non una compromissione.
Errore comune + fix: confondere “legacy” con “exploit immediato”. Anche se è un campanello d’allarme, devi validare nel tuo scenario e rispettare l’autorizzazione.
Detection (segnali): enumerazioni mirate verso porte alte dopo query RPC; in SIEM/IDS, correlazione 111 → porte dinamiche su stesso target.
Hardening/mitigazione: rimuovi/disable NIS se non indispensabile; segmenta e applica ACL; monitora rpcbind e i demoni RPC registrati.
Errori comuni e troubleshooting (permessi, UDP, firewall, falsi negativi) #
In breve: i problemi tipici sono: UDP “silenzioso”, firewall che filtra porte dinamiche, risposte diverse tra TCP e UDP, e
rpcbindlimitato a localhost/reti specifiche.
Problema 1 — rpcinfo: can't contact rpcbind / timeout
#
Perché: devi capire se è down, filtrato o stai interrogando nel modo sbagliato. Cosa aspettarti: errore immediato o timeout.
Comando:
rpcinfo -p 10.10.10.10Interpretazione: se fallisce, verifica prima la visibilità di 111 da quel vantage point.
Errore comune + fix: fidarsi di un singolo scan. Valida sia TCP sia UDP (soprattutto in ambienti Unix).
Comando:
sudo nmap -n -Pn -sS -p 111 10.10.10.10Comando:
sudo nmap -n -Pn -sU -p 111 10.10.10.10Problema 2 — Vedi mountd ma poi non riesci a parlarci
#
Perché: mountd può essere su porta dinamica e filtrata, anche se rpcbind risponde.
Cosa aspettarti: rpcinfo -p mostra la porta, ma le richieste al servizio falliscono.
Comando:
rpcinfo -p 10.10.10.10 | grep mountdInterpretazione: prendi la porta e verifica raggiungibilità (TCP/UDP coerente con l’output).
Errore comune + fix: testare la porta sbagliata o il protocollo sbagliato. Se mountd è udp, testare solo TCP ti porta fuori strada.
Problema 3 — Output “vuoto” o pochissimi servizi #
Perché: in contesti moderni, alcuni setup NFSv4 o hardening restrittivo espongono meno informazioni via RPC.
Cosa aspettarti: poche righe, magari solo rpcbind.
Interpretazione: anche questo è un segnale utile: o il target è hardenizzato o sei in un segmento senza accesso completo alle porte dinamiche.
Quando NON usarlo: se stai perdendo tempo a inseguire “perché non esce niente”, passa a conferme alternative (banner, traffico, log). Per esempio, se sospetti traffico NFS/RPC, cattura pochi secondi di pacchetti in lab e cerca chiamate a 111/2049 (vedi /articoli/tshark/).
Alternative e tool correlati (quando preferirli) #
In breve:
rpcinfoè il “primo sguardo” RPC; poi scegli tool specializzati (NFS, sniffing, enum Windows) in base a ciò che trovi.
Se rpcinfo indica NFS:
- preferisci
showmountper enumerare export e permessi (guida:/articoli/showmount/)
Se devi validare traffico o capire cosa passa davvero:
- usa cattura/analisi con
tcpdump(guida:/articoli/tcpdump/) o analisi più profonda con/articoli/wireshark/
Se sei in ambiente Windows/AD e stai facendo enum SMB/RPC lato Windows:
- spesso ti serve altro (es.
/articoli/rpcclient/o/articoli/smbclient/) perché lì il problema non èrpcbind, ma l’ecosistema SMB/RPC di Windows.
Quando NON usarlo: non usare rpcinfo come sostituto di una strategia di recon. È un tassello: se non lo colleghi a next-step coerenti, resta “rumore informativo”.
Hardening & detection (log, regole, alert, best practice) #
In breve: la difesa efficace è ridurre l’esposizione di
rpcbinde dei demoni RPC, limitare le reti autorizzate e monitorare la correlazione111→ porte dinamiche.
Detection (pratica):
- alert su scansioni ripetute verso
111/tcpe111/udp - correlazione temporale: query su
111seguite da tentativi su2049e su porte alte dinamiche (tipico di NFS/mountd) - baseline: quali program number RPC dovrebbero esistere su quel server? tutto il resto è sospetto
Hardening (pratico):
- filtra
111a livello firewall/ACL e consenti solo subnet autorizzate - disabilita servizi RPC legacy non necessari
- segmenta NFS e riduci gli export; usa controlli moderni e least privilege
- monitora cambiamenti nei servizi registrati su
rpcbind(un demone RPC “nuovo” è un red flag)
Scenario pratico: rpcinfo su una macchina HTB/PG #
In breve: da una
111aperta identifichi NFS/mountd, confermi la reachability e decidi se procedere con enum NFS in modo controllato e tracciabile.
Ambiente: attacker Kali in lab, target 10.10.10.10.
Obiettivo: capire se dietro RPC c’è NFS e qual è la porta reale di mountd.
Perché: ottenere una mappa RPC concreta e non “intuizioni” da una singola porta.
Cosa aspettarti: elenco RPC con nfs e mountd se presenti.
Comando:
rpcinfo -p 10.10.10.10Esempio di output (può variare):
program vers proto port service
100000 4 tcp 111 portmapper
100003 3 tcp 2049 nfs
100005 3 udp 20048 mountdInterpretazione: NFS attivo; mountd su 20048/udp.
Perché: verificare che mountd risponda davvero prima di proseguire.
Cosa aspettarti: “ready and waiting” o errore/timeout.
Comando:
rpcinfo -u 10.10.10.10 100005Risultato atteso concreto: conferma del servizio e decisione operativa di passare a enumerazione export NFS con showmount (in lab) se autorizzato.
Detection + hardening: questo flusso lascia tracce chiare (query su 111 e poi su 2049/porte alte). In produzione si mitiga filtrando 111 e limitando NFS alle sole subnet necessarie.
Playbook 10 minuti: rpcinfo in un lab #
In breve: in 10 minuti passi da “porta 111 trovata” a “mappa RPC + next-step” riducendo errori e falsi negativi.
Step 1 – Conferma del contesto e autorizzazione #
Prima di toccare RPC, assicurati che il target sia parte del lab autorizzato e che l’IP sia corretto (10.10.10.10 nel tuo scenario).
Step 2 – Verifica 111/tcp
#
Perché: se TCP è open, spesso hai un percorso più “deterministico”.
Cosa aspettarti: 111/tcp open se esposto.
Comando:
sudo nmap -n -Pn -sS -p 111 10.10.10.10Step 3 – Verifica 111/udp (se serve)
#
Perché: RPC spesso parla anche UDP; un check UDP evita buchi.
Cosa aspettarti: open|filtered o open (in UDP non sempre è netto).
Comando:
sudo nmap -n -Pn -sU -p 111 10.10.10.10Step 4 – Enumerazione completa con rpcinfo -p
#
Perché: vuoi porte reali + servizi.
Cosa aspettarti: tabella program/vers/proto/port/service.
Comando:
rpcinfo -p 10.10.10.10Step 5 – Triage rapido con rpcinfo -s
#
Perché: riduci rumore, confermi versioni. Cosa aspettarti: servizi principali con versioni supportate.
Comando:
rpcinfo -s 10.10.10.10Step 6 – Verifica attiva del servizio più interessante #
Scegli il servizio “chiave” (es. mountd se stai andando verso NFS) e valida la reachability sul protocollo corretto.
Comando:
rpcinfo -u 10.10.10.10 100005Step 7 – Next-step coerente e controllato #
Se trovi NFS/mountd, passa a enum export con showmount (in lab e solo se previsto dal tuo esercizio). Se invece ti serve capire traffico e comportamenti, cattura pacchetti e analizza (es. /articoli/tcpdump/).
Checklist operativa #
In breve: checklist rapida per non sbagliare: conferma
111, enum, valida, poi scegli la prossima mossa.
- Confermato che il target è un sistema autorizzato (lab/CTF/VM).
- Verificata
111/tcpcon scan mirato. - Verificata
111/udpse TCP è chiusa o se sospetti RPC via UDP. - Eseguito
rpcinfo -pper ottenere porte reali. - Eseguito
rpcinfo -sper triage rapido di versioni/servizi. - Annotati
program number,protoeportdei servizi interessanti. - Validato il servizio chiave con
rpcinfo -torpcinfo -u. - Se NFS presente, deciso se procedere con enumerazione export (es.
showmount). - Considerata cattura traffico se output ambiguo (
tcpdump/tshark). - Preparati note per detection: sequenza
111→ porte dinamiche. - Segnalate mitigazioni: filtraggio
111, segmentazione, disable servizi legacy.
Riassunto 80/20 #
In breve: 5–8 azioni che coprono l’80% degli scenari
rpcinfoin lab.
| Obiettivo | Azione pratica | Comando/Strumento |
|---|---|---|
| Confermare RPC bind | Check rapido su 111/tcp | nmap -sS -p 111 10.10.10.10 |
| Evitare falsi negativi | Check anche su 111/udp | nmap -sU -p 111 10.10.10.10 |
| Mappare servizi + porte | Lista completa RPC | rpcinfo -p 10.10.10.10 |
| Triage versioni | Vista compatta | rpcinfo -s 10.10.10.10 |
| Validare servizio specifico | Test TCP sul service name | rpcinfo -t 10.10.10.10 mountd |
| Validare servizio specifico | Test UDP sul program number | rpcinfo -u 10.10.10.10 100005 |
| Passare a NFS recon | Enumerare export (se presente) | showmount -e 10.10.10.10 |
| Capire cosa succede davvero | Sniff/cattura mirata | tcpdump / wireshark |
Concetti controintuitivi #
In breve: errori “classici” che fanno perdere tempo e come evitarli in lab.
- “Se
111/udpnon risponde allora è chiuso” No: UDP può essere silenzioso per design o per filtri. Valida con più segnali e, se puoi, da un vantage point migliore. - “Se un servizio è registrato allora è sicuramente raggiungibile”
Non sempre: registrazione RPC e raggiungibilità reale possono divergere. Usa
rpcinfo -t/-uper confermare. - “La porta di
mountdè sempre quella standard” Spesso è dinamica. Il punto dirpcinfo -pè proprio scoprire la porta reale in quel momento. - “
rpcinfoè già ‘attacco’” È enumeration. In un report, però, è comunque un segnale di esposizione: la difesa è filtrare e ridurre superficie RPC.
FAQ #
In breve: risposte rapide ai dubbi più frequenti quando usi
rpcinfoin lab.
D: rpcinfo -p va in timeout. Che faccio?
R: Prima verifica 111 in TCP e UDP. Se 111/tcp è open ma rpcinfo time-outa, potresti avere filtri applicativi o ACL: cambia vantage point o usa test mirati con rpcinfo -t/-u.
D: Vedo mountd ma showmount non funziona.
R: Potresti avere mountd filtrato sulla porta dinamica o policy NFS restrittive. Inizia validando mountd con rpcinfo -u sul program number e poi verifica reachability della porta riportata da rpcinfo -p.
D: Posso usare rpcinfo anche su sistemi moderni?
R: Sì, ma l’output può essere più limitato se l’ambiente è hardenizzato o se alcuni servizi RPC legacy non sono usati. Anche “poco output” è informazione utile.
D: Perché devo controllare UDP?
R: Perché molte implementazioni RPC/NFS supportano UDP oltre a TCP, e ignorarlo crea falsi negativi in fase di recon.
D: rpcinfo -t host mountd fallisce ma rpcinfo -u host 100005 funziona.
R: È normale se quel servizio è esposto solo in UDP o se TCP è filtrato. Segui il protocollo che vedi in rpcinfo -p.
Link utili su HackIta.it #
In breve: articoli correlati per completare il workflow (dalla discovery alla validazione).
- Showmount: scoprire condivisioni NFS esposte
- ARP-Scan: host discovery in LAN per pivoting
- Netdiscover: discovery host via ARP
- Tcpdump: analizzare traffico da terminale
- TShark: analisi traffico in CLI
- Snmpwalk: enumerazione massiva SNMP
In coda (pagine istituzionali):
- /supporto/
- /contatto/
- /articoli/
- /servizi/
- /about/
- /categorie/
Riferimenti autorevoli #
- https://man7.org/linux/man-pages/man8/rpcinfo.8.html
- https://man7.org/linux/man-pages/man8/rpcbind.8.html
CTA finale HackITA #
Se questa guida ti ha fatto risparmiare tempo nel recon RPC/NFS in lab, supporta il progetto: /supporto/
Vuoi accelerare davvero (stile OSCP) con un percorso guidato su enumerazione e catene di attacco realistiche? Formazione 1:1 qui: /servizi/
Per assessment aziendali e penetration test (interni/esterni) con report e remediation: trovi tutto su /servizi/